For those of you who are here because you read Part 1 of A Day with Cypress, welcome. For those who haven’t yet read it, why not head back and join me from the beginning of this journey. If that’s not for you, and you like to go rogue, welcome, but don’t expect a ‘last time on…’ style intro, you’re coming in hot!
In Part 1 we stopped before getting to points 2 and 3 of the list of objectives I’d set myself on that fateful day. So we’ll rectify that in Part 2 by covering item 2 in the list.
To put a Cucumber implementation on top to author the scripts- To look again at stubbing calls at runtime
- To look at using snapshots instead of explicit assertions
One of the fantastic features of Cypress, and a real USP when comparing it to a Selenium based library, is that it runs within the browser and has access to the javascript that your application is built from, at test time. This provides users with a whole host of possibilities to solve testability challenges, for which we would otherwise need to find alternative and potentially clunkier solutions. Injecting test data is one of those testability challenges. I’m going to guess that most software testers can recall a time in their career when they’ve hit their heads against a brick wall trying to get good test data in to their application.
It would appear the team at Cypress have experienced this themselves because it’s one of the most useful parts of their library. Cypress comes with the ability to intercept and replace some requests at test time and above all it’s really simple to start using. Let’s look at an example.
Testing the UI or Through the UI
Being cheeky I’ve picked the Royal Mail Find a Postcode feature to demonstrate this. When using the feature, as you type in to the text box, each letter you type will initiate an XHR request which, based on the post code you’ve begun to enter, returns a suggested list of addresses to show to the user.
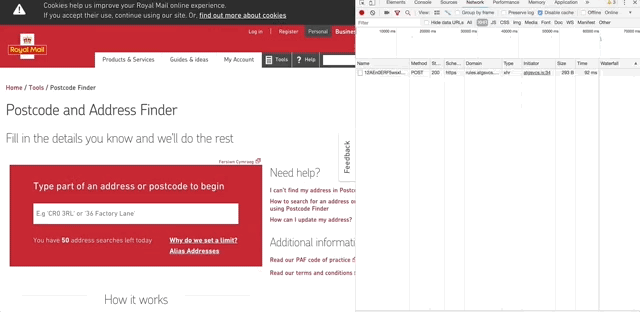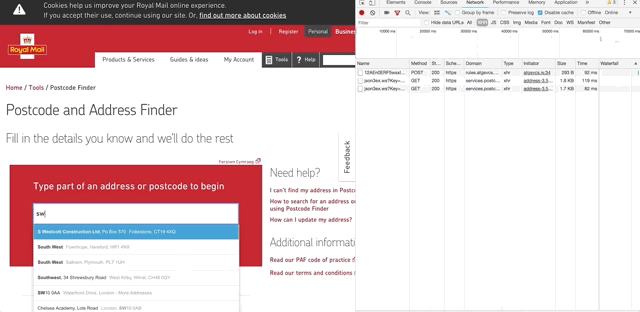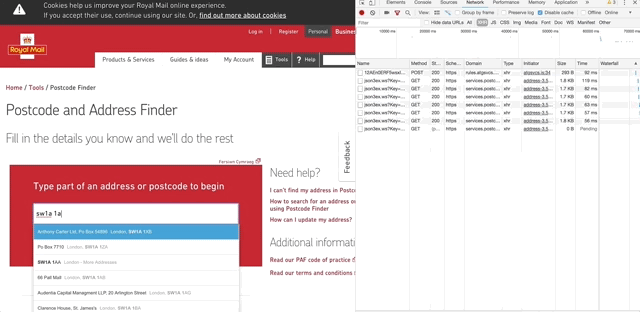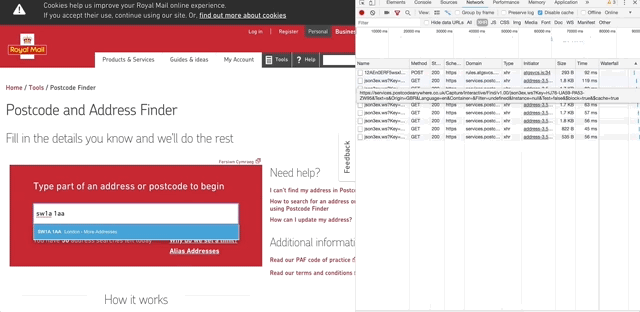
When it comes to testing this feature, I might consider the following sample of identified risks:
- When I type, the expected request isn’t sent to the service
- When we get a response, it doesn’t contain useful information
- The UI doesn’t render useful information appropriately
Risk 2 doesn’t need the UI to explore and verify. I could quite happily send requests to the end point, using a tool like Postman or writing some code and process the response. This will give me the same level of confidence in what I discover as it will if I had I tested ‘through’ the UI. Amongst other things, by removing the UI from the process, I reduce the complexity of the setup and reduce the risk that something in the UI blocks my testing.
However, risks 1 & 3 are tightly coupled to the UI. If the UI isn’t mapping the typed text to the request to the service correctly, then that is a UI issue. Similarly, if the UI doesn’t render the appropriate information to the user based on the response from the service, then that is also a UI issue. So, based on the assumption (as explained above) that I don’t need to test through the UI to test risk 2, then I can make the logical assumption that I don’t actually need the service to test the UI.
In summary:
If I only want to test the UI, then I may not need the integrated service to be up and running. However, I do need the information that is going to be processed by the UI.
In setting this principle, we achieve another benefit and that is one of determinism. For any check that might go in to our pipeline, we want to reduce the potential for noise (unwanted or useless information) as much as possible. Checks should fail because we’ve introduced a problem, not because our test data and setup isn’t deterministic.
There are many ways we can achieve this:
- Using hand rolled local stubs which we proxy a locally hosted version of the UI to
- Using a hosted service such as GetSandbox, configuring the application or environment to point to a different service end point or address
- Seeding data in to the integrated service and therefore completing a fully top-to-bottom information loop.
Cypress allows us to do option 1 but really easily. All we need to do is add to a script steps 1 & 2 below and configure them to intercept the appropriate service call and replace the response.
- Start up the Cypress routing server with cy.server()
- Define a route that you want to intercept with cy.route()
- Execute the actions necessary to get the UI to send the request
- Assert on the expected outcomes
All good in theory but I know you’d like to see an actual example.
Testing the Address Finder
To configure the steps correctly we need two additional pieces of information:
- The request that’s going to be sent to the service
- An example response that we want to modify to suit our needs
In this case, if the user types ‘s’ in to the text box, the following request is sent to the service:
https://services.postcodeanywhere.co.uk/Capture/Interactive/Find/v1.00/json3ex.ws?
The request also contains a number of parameters, but I’ve omitted them for this example. If you want to explore more, you can find this yourself using the Network tab of your favourite browsers Dev Tools.
The response from that request contains an array of objects. Each object looks like this:
{
"Id":"GB|RM|A|5262327",
"Type":"Address",
"Text":"South, Pannels Ash",
"Highlight":"0-5",
"Description":"Pentlow, Sudbury, CO10 7JT"
}
Through a little reverse engineering, we can see that the Suggested Addresses list displays the Text and Description properties of each of the returned objects. *Ideally, if you were working on this feature, you’d not have to guess this.
So taking a really simple test case:
Given the user is on the ‘find a postcode’ page
When the user enters ‘s’ into the text box,
Then we should be shown a suggested addresses list that contains the expected addresses for ‘s’.
As discussed, this isn’t great if you’re using a fully integrated system and can’t control the information that you get back. So instead we should author the test case to suit our testing needs, then tell Cypress to help us achieve the setup needed.
Our test case now becomes:
Given the user is on the 'find a postcode' page
When the user enters 's' into the text box
Then we should be shown a suggested address
of 'Buckingham Palace'
with text 'Where the Queen Lives'
Let’s look at the code, starting with the step definition for the When step.
When('the user enters {string} into the text box', (postcode) => {
cy.server({
delay: 1000
});
cy.route('**/Capture/Interactive/Find/v1.00/json3ex.ws**',
'fixture:bPSuggestedAddress.json').as('getSuggestedAddresses');
cy.get('[data-di-id="#cp-search"]').type(postcode);
cy.wait('@getSuggestedAddresses')
});
Let’s look at what we’ve got. Firstly there’s a call to cy.server which we’ve configured to have a 1000ms delay before any response is provided. In this case I’m using the delay to emulate a slow round trip from request to response. It’s not necessary for this example but it helps to demonstrate a pattern explained later on. Once the server is up and running, we then need to specify a route that we’d like to intercept. To setup a route for our needs, we need to first help it identify the correct request we want to manipulate. There are three ways to pattern match a URL for a request: exact strings; regex and glob. In our example I’ve asked the route to ignore the top level domain and any parameters.
Now that we know how to intercept the request, we need to know what to do with it. cy.route is a very extensible method, allowing the user a number of options to satisfy the testing needs. We can inline responses directly into the method, but unless you’re replacing the response with an empty object {} then your code is going to look quite clunky. Your second options is to pass in a callback which will be called when the route is intercepted, allowing you access to the response data and manipulate it as needed. Option three is the one I’ve used and Cypress call it Fixtures. A fixture, in its basic terms, is data in a file. This is a powerful technique because it helps you manage potentially complex JSON objects away from your code but makes it really easy to use them.
As you can see, I’ve configured cy.route to replace the response with the contents of the fixture ‘bPSuggestedAddress.json’. This file lives in the folder /fixtures and contains the following object
{
"Items":[
{
"Id":"GB|RM|A|2846114",
"Type":"Address",
"Text":"Buckingham Palace",
"Highlight":"0-1",
"Description":"Where the Queen Lives"
}]
}
Dead simple I’m sure you’ll agree. We’ve also given this route an alias. These are nice little shortcuts that can be later referenced in code, and they also turn up in the Cypress test runner, so are great for marking up steps to easily find them.
Continuing the step definition, we type the letter ‘s’ into the appropriate text box and then ask the step definition to wait until the response has been intercepted. Remember that alias I just mentioned? Well because I’ve set up the route with one, I can now ask Cypress to wait until that alias has completed. Don’t be afraid to do this. Remember, this isn’t some arbitrary wait which could be indefinite, instead it will wait for exactly the time we’ve specified. In this case we’ve put in a delay of 1000ms for the server to intercept our request and send back the desired response. If we hadn’t put in a delay, that response would be sent back immediately.
And that’s the step completed. The last step in the script is:
Then we should be shown a suggested address
of 'Buckingham Palace'
with text 'Where the Queen Lives'
And here’s how I’ve implemented it:
Then('we should be shown a suggested address of {string} with text {string}',
(address, text) => {
expect(cy.get('body > div.pca > div:nth-
child(4)').children().should('have.length', 3))
cy.get('body > div.pca > div:nth-child(4) > div.pcaheader')
cy.get('body > div.pca > div:nth-child(4) > div.pcafooter')
cy.get('#cp-search_results_item0').parent().should('have.id', 'cp-
search_results')
cy.get('#cp-search_results_item0').should('contains.text', address + text)
cy.get('#cp-search_results_item0 > span').should('have.text', 'Where the
Queen Lives')
})
These are all specifics related to how the ‘suggested addresses’ component works, so don’t worry too much about them, but I think we can both agree that it looks quite clunky and I definitely know that there’s some parts of the expected implementation that I’ve not covered. Which begs the question, how can we do that better? In Part 3 of this series, I’ll take you into the realms of snapshot testing. If you’re familiar with component based snapshots with Jest and Enzyme, then you’ll have a good idea of where this will go.
So there you go, you’ve now learnt how to use the basics of request and response manipulation with Cypress. It’s not a tool that you’ll want to use all of the time, but in the right situation and the right context, it’s an extremely powerful addition to your tool box. Also, because it’s so simple and quick, it’s a great tool to actually aid testing (not checking). That means you can use it to help you when you’re exploring the application and want to run ad-hoc experiments on your application. If some of those experiments end up as pipeline checks then great, but don’t feel the need or to be pressured into assuming that every piece of automated testing code you write has to go into the pipeline, but that’s another post for another time.
Thanks again for reading and I do hope that you found this useful. Please leave your comments below.
I’ve also considered turning these into vlogs, so if that’s something you think would be worthwhile, please get in touch and let me know.

Really good article! Thanks a lot for writing it! It’s helping me in my first steps with Cypress. I just wish you’d have finished with the third item on the list (using snapshots)
LikeLike